Repeated
Measures
I. Why do repeated measures experiments?
A. Power: subjects serve as their own controls; effects of
treatments are measured against the mean effect of all the treatments combined
on the subject.
B.
Efficiency
C. Example:
SR(AF) X BF
N=30, a=3, b=3, n=10
(3 groups of 10 subjects receiving
each of 3 treatments)
Source E(MS) df ___
Error Line
1. A nbs2A + bs2S(A) a-1 = 2
2
2. S(A) bs2S(A) a(n-1)= 27
3. B nas2B + s2S(A)B b-1
= 2
5
4. A X B ns2AB + s2S(A)B a-1)(b-1)= 4 5
5. S(A) X B s2S(AB) (b-1)a(n-1)=54
If different subjects were run in each treatment,
one would need 3 X 30= 90 subjects.
SR(AF
X BF) Factorial N=90
Source E(MS) df _
Error
Line
1. A nbs2A + s2S(AB) a-1=2 4
2. B nas2B + s2S(AB) b-1=2
4
3. A X B ns2AB + s2S(AB) (a-1)b-1)=4 4
4. S(A X B) s2S(A)B ab(n-1)=81
For the test of B to reach significance in the
repeated measures design one would need an F.05(2,54)=3.19. For this test to reach significance in the
factorial design, one would need an F.05(2,81)=3.12. So, little power is lost at a great savings
in subjects. Also, note that if a
smaller number of subjects are run in the factorial design, there is a
substantially larger loss of power. For
example, if n=4 and so N=36, the test of B would need an F(2,27) value
of 3.34 to reach significance at the .05 level.
II. Model for repeated measures with 1 repeated
factor.
|
|
Treatment |
|
|||||||
Subject |
1 |
... |
j |
... |
k |
|
|
|||
|
1 |
y11 |
|
y1j |
|
y1k |
|
|
|||
|
. |
|
|
|
|
|
|
|
|||
|
i |
yi1 |
|
yij |
|
yik |
|
|
|||
|
. |
|
|
|
|
|
|
|
|||
|
N |
yni |
|
ynj |
|
ynk |
|
|
|||
|
|
|
|
|
|
|
|
|
|||
SStotal= SS(yij-![]() ..)2
..)2

![]() SSb.people= kS(
SSb.people= kS(![]() i.-
i.- ![]() ..)2
..)2

![]()
![]()
![]() SSw.people= SS(yij-
SSw.people= SS(yij-![]() i.)2
i.)2
![]()
![]() SStotal=SSb.people+SSw.people
SStotal=SSb.people+SSw.people
SStreat= nS(![]() .j-
.j-![]() ..)2
..)2
SSresidual = SS[(yij-![]() ..)-(
..)-(![]() i.-
i.- ![]() ..)-(
..)-( ![]() .j-
.j-![]() ..)]2
..)]2
SSw.people=SStreat +
SSresidual
Model: SR X TF
Source E(MS) df Error
Line
1. S ts2S n-1
2. T ns2T + s2ST k-1
3
3. S X T s2ST
(n-1)(k-1)
III.
Assumptions of Univariate Repeated Measures
A. ANOVA assumptions of:
1. Homogeneity of
variances
2. Errors are independently
and identically distributed as N(0, s2).
3. Subject effects are
independent and distributed as N(0, s2).
B. Additional assumption of sphericity.
1. Observations may covary,
but the degree of covariance must remain the same across treatments( e.g. no
carry-over effects).
2. If the covariances are heterogeneous,
the error term will generally be an underestimate and F tests will generally be
positively biased (cf. Box 1954).
IV.
Comparisons between treatments.
A. Often the hypothesis of interest in a repeated
measures design, like hypotheses in factorial designs, does not correspond to
the tests for main effects. In this
case use a contrast.
MScontrast = 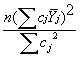
where n=number of observations in the mean
1.
MScontrast can be tested against the standard error term for the corresponding
effect (e.g. MSST).
2.
MScontrast can also be tested against deviations from the expected
trend. This method treats all of the
variance not attributed to the contrast(s) as error. For example, to test a linear contrast by the second method, calculate:
SSdev.linear = SSST + (SST-SSlinear),
df(dev.linear)= dfST+dfT-1 =
[(n-1)(k-1)]+(k-1)-1 = n(k-1)-1
MSdev.linear= SSdev.linear/df(dev.linear)
When the degrees of freedom are large (say over 30),
then the two approaches do not differ.
Using this procedure tends to negatively bias F-tests because the
denominators are often too large.
3. One could
also use a multivariate approach to testing the contrast. This approach is equivalent to creating a
new variable that is a linear combination of the dependent variables using the
contrast weights ( y* = ci *yijk ) and then performing an
F-test to test whether the mean of this
new variable is different from zero (this is what many computer programs
report).
V. Example (Winer p268)
Person Drug
1 Drug 2 Drug 3 Drug 4 Mean
1 30 28 16 34 27
2 14 18 10 22 16
3 24 20 18 30 23
4 38 34 20 44 34
5 26 28 14 30 24.5
Mean 26.4 25.6 15.6 32 24.9
SSbetween S= 4(170.2)=680.8
SSwithin S = 811
SSdrugs = 5 (139.64)=698.2
SSSXD = 112.8
SStotal = 1491.8
Source SS df
MS F
Between S 680.8
4 170.2
Within S 811 15 54.07
Drugs
698.2 3 232.73 24.76
S X D
112.8 12 9.4
Total 1491.8 19
If we assume that drugs 1-4 are really 4 dosage
levels of the same drug, it makes sense to test for trends.
Drug dosage
26.4 25.6 15.6 32
Contrast Weights
Linear -3 -1 1 3
Quadratic
1 -1 -1 1
Cubic -1 3 -3 1
Tests against SXD
F=MScontrast/MSSXD
MSlin= 5(6.8)2=
11.56 1.23
20
MSquad= 5(17.2)2 =
369.8 39.34**
4
MScubic = 5(35.6)2 =
316.84 33.7
**
20
Total =
698.2
Tests against deviations from trend:
SS dev.lin
= (SSresidual + SSdrugs)- SSlin
799.4 =112.8 + 698.2 - 11.56
SS dev.quad
= (SSresidual + SSdrugs)- SSlin-SSquad
429.64 = 112.8 + 698.2 - 11.56-369.8
SS dev.cubic = (SSresidual + SSdrugs)-
SSlin-SSquad-SScubic
= SSres=112.8
Flin = MSlin = 11.56
=
.20
df=(1,n(k-1)-1)=(1,14)
Msdev.lin
799.44/14
Fquad = MSquad = 369.8
= 11.19**
df=(1,n(k-1)-1-1)=(1,13)
MSdev.quad 429.64/13
Fcubic= MScubic = 316.84 = 33.7** df=(1,n(k-1)-1-1-1)=(1,12)
MSdev.cubic 112.8/12
Multivariate approach
SS
DF MS F P
linear 11.560 1 11.560 3.074 0.154
error 15.040 4 3.760
quadratic 369.800 1
369.800 26.797 0.007
error 55.200 4
13.800
cubic 316.840 1
316.840 29.778 0.005
error 42.560 4
10.640
VI. Violations of sphericity
A. Assumptions
For the typical F ratio used in univariate repeated
measures analyses to be exact, the data must demonstrate homogeneity of
treatment differences; that is, given any two treatments i and j,
s2 (vi-vj) is constant. If the covariance matrix of the data is
symmetrical (i.e., has compound symmetry) then this assumption will be
met. For example, if the covariance
matrix for a design with three treatments were to have compound symmetry, it
would have the form:
T1 T2 T3
T1 s2 ps2 ps2
T2 ps2 s2 ps2
T3 ps2 ps2 s2
where p=constant.
Although compound symmetry is not necessary for the assumptions of a
repeated measures analysis F-test to be met, it is sufficient. Compound symmetry is violated when one
treatment covaries differently with some treatments than with other
treatments. This may occur when
treatments are not presented in a counterbalanced order (e.g. a latin square is
not used). If the covariances are
heterogeneous, the error term will generally be an underestimate and the F
tests will generally be positively biased (cf. Box 1954).
B. Testing for violations
Compound symmetry can be tested by inspection and by
several summary measures, such as Box's (1950) extension of Bartlett's test for
homogeneity of variance.
C. Box (1950) test of compound symmetry
1. Take sample variance/covariance matrix S (pooled over levels of any grouping
factors).
![]()
![]() 2. Construct S'=
var...cov...cov
2. Construct S'=
var...cov...cov
.
. . .
cov...var...cov
.
. . .
cov...cov...var
where var=mean of s2i (main
diagonal) of S
cov=mean of s2ij (off diagonal elements) of S
3. Calculate:
M=
-(N-p)ln(|S|/|S'|) | | = determinant of
matrix
C= q(q+1)2(2q-3)
6(N-p)(q-1)(q2+q-4)
df=
q2+q-4
2
where N= number of subjects
p= number of groups
q= number of repeated measures treatments
4. Evaluate C2(df)=(1-C)M
If this is significant, then the matrix violates the
compound symmetry assumption.
D. Correcting
for violations
1. Use multivariate
techniques: MANOVA, Hotelling T2.
These are extensions of ANOVA and t-test for multivariate data.
2. Set bounds on the true significance of the F
test (Box 1954).
a. In a repeated measures design, the F ratio for a
within-subjects effect is distributed as F[dfnumerator e,dfdenominator e] where 1/dfnumerator < e < 1. e measures the degree to
which the covariance matrix deviates from compound symmetry.
b. If e=1, then F ratio has normal
df -- this yields a lower bound on the alpha level.
c. When e=1/dfnumerator , the numerator of
the F ratio has 1 degree of freedom -- this yields an upper bound on the alpha
level (maximum heterogeneity of covariances).
d. The true significance of the effect will lie
between that provided by these tests.
3. Example
for S X T design
a. F ratio s2T/s2ST distributed as F[(k-1) e,(k-1)(n-1) e] where 1/(k-1) < e < 1; k is the number of treatments.
b. If e=1, then F ratio has normal
df -- this yields a lower bound on the alpha level.
c. If e=1/(k-1), then the F ratio has 1,n-1 degrees
of freedom -- this yields an upper bound on the alpha level.
d. The true significance of the effect will lie
between that provided by these tests.
The F(k-1,(k-1)(n-1)) level is too liberal, while the F(1,n-1) level is
too conservative.
4. Estimate
the true significance of the F-test (estimate e).
a.
Box's (1954) e^ aka Greenhouse-Geisser F
e^ = ![]()
where
sij= is the i,j element
in the sample variance/covariance matrix.
sii= mean of variances in sample
(main diagonal in matrix)
s..=
mean of all variances and covariances in sample
si.= mean of all variances and
covariances with variable i (row of matrix)
k = number of treatments
n = number of subjects
This procedure tends to underestimate the true e and hence to underestimate the significance
of a result, but not by as much as the lower bound approximation of 1/k-1
above.
b. Huynh-Feldt e~
e~ = n(k-1)
e^ -2
(k-1)[n-1-(k-1) e^]
In general, e~ tends to overestimate e. In
fact, e~ can be larger than 1. When this occurs, e~ is set to 1. e~ will usually be larger
than e^ so it will increase the power and the
possibility of Type I errors in the analysis.